Árvore de Decisão em Aprendizado de Máquina
Uma árvore de decisão de aprendizado do Python Mache é avaliada e exemplos são fornecidos para ajudar na compreensão. Uma árvore de decisão é uma das ferramentas mais poderosas e populares para classificação e previsão.
As árvores de decisão são árvores semelhantes a fluxogramas em que cada nó interno identifica um teste em um atributo, cada ramificação representa o resultado e cada nó folha (nó terminal) identifica a classe.
Árvore de Decisão do Python
Mostraremos como criar uma “ árvore de decisão ”. Você pode usar uma árvore de decisão como uma ferramenta para ajudá-lo a tomar decisões com base em suas experiências anteriores.
Por exemplo, uma pessoa pode decidir se vai ou não a um concerto de música.
Temos a sorte de que a pessoa de exemplo registrasse todas as vezes que havia um show de música na cidade. Além disso, ele/ela adicionou qualquer informação que tenha sobre o cantor.
| idade do cantor | Experiência do cantor | Classificação | Região de Concerto | Ir |
| 26 | 5 | 8 | CA | SIM |
| 32 | 2 | 2 | EUA | NÃO |
| 40 | 10 | 7 | N | NÃO |
| 28 | 6 | 3 | EUA | SIM |
| 19 | 1 | 9 | EUA | SIM |
| 43 | 3 | 4 | CA | NÃO |
| 33 | 7 | 6 | N | SIM |
| 55 | 15 | 8 | CA | SIM |
| 63 | 20 | 9 | N | SIM |
| 59 | 7 | 8 | N | SIM |
| 22 | 2 | 9 | EUA | NÃO |
| 29 | 6 | 2 | CA | SIM |
| 31 | 3 | 8 | EUA | SIM |
| 62 | 5 | 4 | CA | Não |
| 47 | 8 | 7 | EUA | SIM |
O programa Python agora pode construir uma árvore de decisão usando esse conjunto de dados , o que pode ajudar a determinar se vale a pena assistir a novos shows de música ou não.
Como funciona?
Para ler o conjunto de dados com pandas , primeiro importe os módulos necessários :
O conjunto de dados deve ser lido e impresso da seguinte forma:
Example
Todos os dados devem ser numéricos ao fazer uma árvore de decisão.
Concert Region e Go não são colunas numéricas, então precisamos convertê-las em numéricas.
Map () em Pandas pega um dicionário contendo informações sobre como os valores devem ser convertidos.
{'CA': 0, 'USA': 1, 'N': 2}
'CA' torna-se 0, 'EUA' torna-se 1 e 'N' torna-se 2.
Valores numéricos podem ser convertidos de valores de string da seguinte maneira:
Example
Depois disso, precisamos separar a coluna de destino da coluna de recurso.
Nossa coluna de destino é a coluna com os valores previstos, enquanto as colunas de recursos são as colunas a partir das quais tentamos prever.
Uma coluna de recurso é varx e uma coluna de destino varia:
Example
Nossa árvore de decisão agora pode ser criada de acordo com os detalhes que fornecemos e podemos salvá -la como um arquivo .png:
Salve a Árvore de Decisão como uma imagem e mostre-a:
Example
Resultado explicado
Ao analisar suas decisões anteriores, a árvore de decisão calcula sua probabilidade de assistir ou não ao show de um determinado cantor.
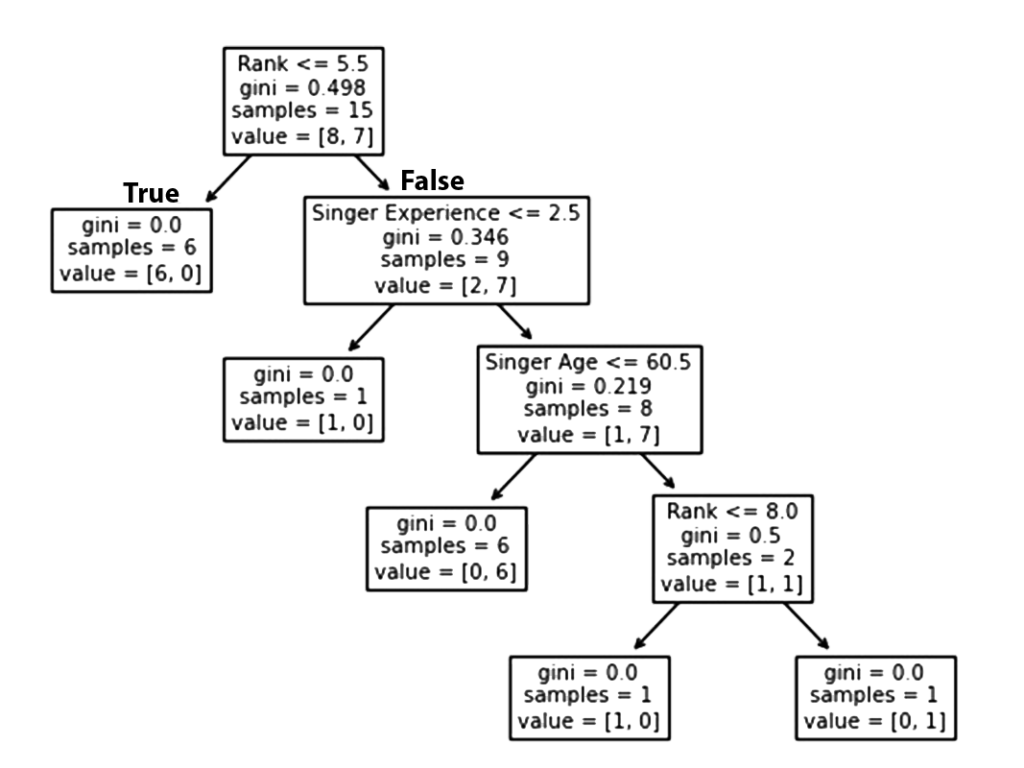
Aqui estão os diferentes aspectos da árvore de decisão:
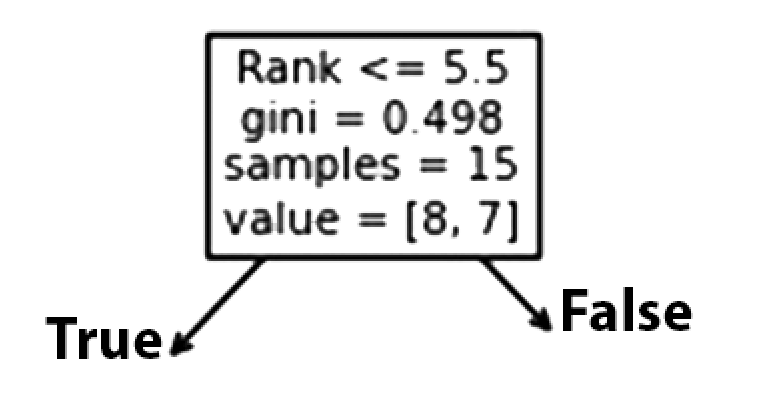
Classificação
Um cantor com um Rank de 5,5 ou inferior seguirá a seta Verdadeiro (à esquerda) e o restante seguirá a seta Falso (à direita).
A qualidade da divisão é determinada por gini = 0,498 , que é sempre um número entre 0,0 e 0,5 , onde 0,0 indica que todas as amostras receberam a mesma resposta, enquanto 0,5 indica que está centralizado.
Considerando que esta é a primeira etapa do processo de seleção, restam 15 cantores neste momento.
Este valor indica que destes 15 cantores, 8 terão um “NÃO”, enquanto 7 terão um “JÁ”.
Gini
O GINI é um método para dividir as amostras, mas existem muitos outros. Este tutorial demonstra o método GINI.
O método de Gini usa a seguinte fórmula:
Gini = 1 - (x/n)2 - (y/n)2Tomando x como o número de respostas positivas (“ GO “), n como o número de amostras, e y como o número de respostas negativas (“ NÃO “), o seguinte cálculo pode ser feito:
1 - (7 / 13)2 - (6 / 13)2 = 0.497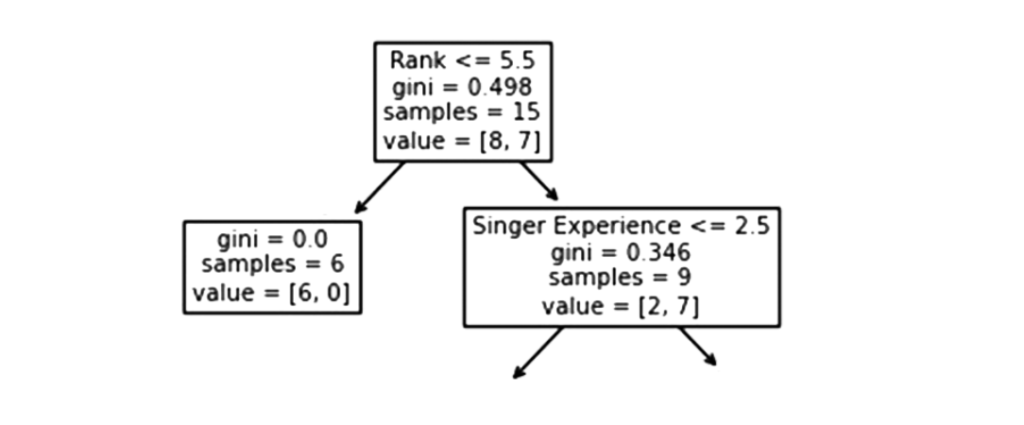
Em seguida, há duas caixas, uma para cantores com ' Rank ' inferior a 5,5, e outra para os demais.
Verdadeiro – 6 cantores terminam aqui:
Um valor de Gini de 0,0 implica que o mesmo resultado foi obtido por todas as amostras.
Um tamanho de amostra de 6 indica que restam apenas seis cantores neste ramo (6 cantores com classificação de 5,5 ou inferior).
Neste caso, 6 resultará em um “NÃO” e 0 resultará em um “GO”.
Falso – 9 Cantores Continuam:
Experiência do cantor
No contexto da experiência dos cantores , um valor inferior a 2,5 significa que os cantores com um valor de experiência de canto inferior a 2,5 anos seguirão a seta à direita e os restantes seguirão a seta à esquerda.
O valor gini de 0,346 indica que 34,6% das amostras irão em uma direção.
Um tamanho de amostra de 9 indica que restam 9 cantores neste ramo (9 cantores com uma classificação de canto superior a 5,5).
De acordo com value = [2, 7] apenas dois desses nove cantores receberão um “NÃO” enquanto os outros sete receberão um “GO”.
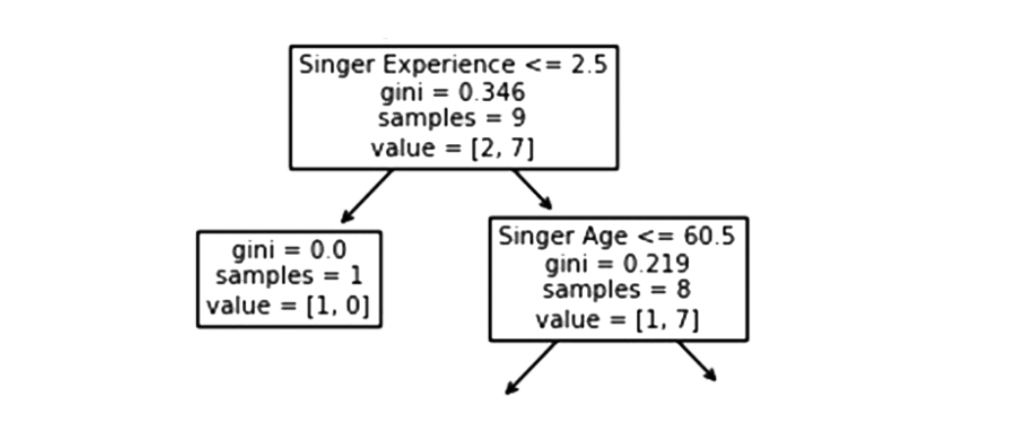
Verdadeiro – 8 Cantores Continuam:
idade do cantor
Quando a idade for igual ou inferior a 60,5 anos , os cantores com idade igual ou inferior a 60,5 seguirão a seta à esquerda . Aqueles com mais de 60,5 anos seguirão a seta para a direita.
Um valor de Gini de 0,219 indica que 21,9% das amostras vão em uma única direção. Um tamanho de amostra de 8 significa que restam 8 cantores no ramo.
O valor de [1, 7] indica que desses 8 cantores, um receberá um “NÃO” e 7 um “GO”.
Falso – Mais um cantor termina aqui:
Gini = 0,0 indica que todas as amostras têm o mesmo resultado.
A contagem de amostra de 1 significa que restam quatro cantores neste ramo.
O valor = [1, 0] indica que 1 Singers, 1 receberá um “ NO ” e 0 receberá um “ GO ”.
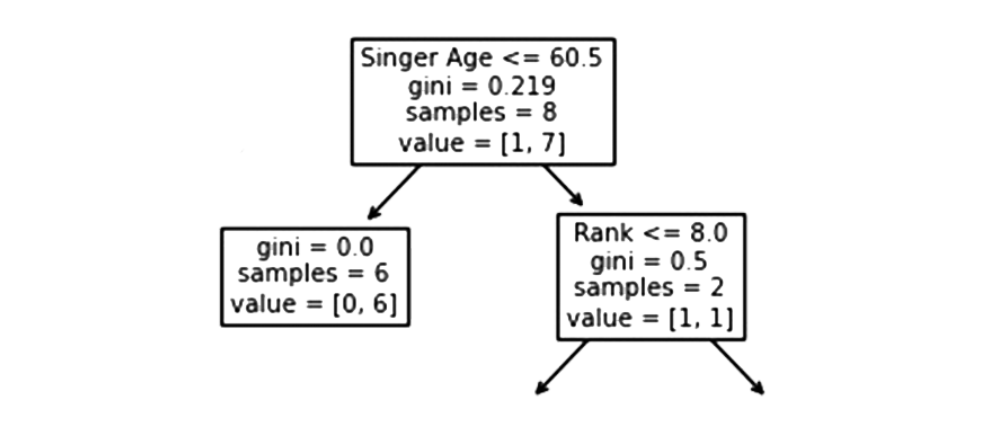
Verdadeiro – 6 cantores terminam aqui:
Um valor Gini de 0,0 indica que todas as amostras produziram o mesmo resultado.
O tamanho da amostra de 6 indica que restam seis cantores neste ramo (6 cantores com menos de 60,5 anos ).
O valor de [0, 6] significa que desses 6 cantores, 0 receberá um “NÃO” e 6 receberá um “ GO ”.
Falso – 2 Cantores Continuam:
Classificação
Cantores com 8,0 ou menos de classificação seguirão a seta para a esquerda, enquanto todos os demais seguirão a seta para a direita.
Gini = 0,5 indica que 50% das amostras irão em uma direção.
O valor amostral de 2 indica que restam dois cantores neste ramo (2 cantores com mais de 60,5 anos ).
Neste caso, o valor de [1, 1] indica que dos 2 cantores, um receberá um “ NO ” e o outro receberá um “ GO ”.
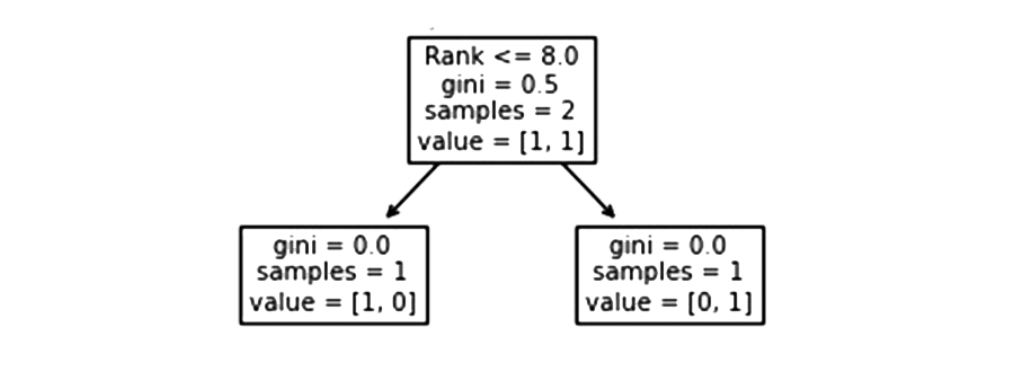
Falso – 1 cantor termina aqui:
Um valor de Gini de 0,0 implica que o mesmo resultado foi obtido por todas as amostras.
O número de amostras = 1 indica que resta apenas um cantor neste ramo (com Rank acima de 8,0).
O valor [1, 0] significa que 1 recebe um “NO” e 0 recebe um “ GO ”.
Verdadeiro – 1 cantor termina aqui:
Um valor de Gini de 0,0 implica que o mesmo resultado foi obtido por todas as amostras.
A partir de agora, resta apenas um cantor neste ramo (1 cantor com classificação 8,0 ou inferior).
O valor de [0, 1] indica que 0 recebe um “ NO ” e 1 recebe um “GO”.
Prever valores
Uma Árvore de Decisão é útil para prever novos valores.
Você pode recomendar um show com uma cantora americana de 35 anos, que tem 12 anos de experiência como cantora e 9 na escala de canto?
Para prever novos valores, use o método predict():
Example
No caso de um nível 5 de canto, qual seria a resposta?
Example
Resultados Diferentes
Depois de executar a Árvore de Decisão várias vezes, você verá que mesmo os mesmos dados a alimentam com resultados diferentes.
Por causa da Árvore de Decisão , não podemos ter 100% de certeza da resposta, pois ela não nos dá 100% de certeza. Com base na probabilidade de um resultado, e a resposta será diferente dependendo da probabilidade desse resultado.
Vantagens e Desvantagens da Árvore de Decisão
Vantagens da árvore de decisão:
- Uma árvore de decisão pode gerar regras fáceis de entender.
- Nas árvores de decisão, a classificação é realizada sem muita computação.
- As variáveis contínuas e categóricas podem ser manipuladas por árvores de decisão.
- A previsibilidade e a classificação podem ser melhoradas usando árvores de decisão.
Desvantagens da árvore de decisão:
- Ao estimar atributos contínuos, as árvores de decisão são menos apropriadas.
- O uso de árvores de decisão pode levar a erros quando há muitas classes e um número limitado de exemplos de treinamento ao lidar com problemas de classificação.
- O treinamento de uma árvore de decisão pode ser computacionalmente caro. O crescimento de uma árvore de decisão é computacionalmente intensivo. Para encontrar a melhor divisão em cada nó, cada campo de divisão candidato deve ser classificado.
